Le fonctionnement du web



Le fonctionnement du web
Le fonctionnement du web
Le web signifie toile en français et correspond à l’ensemble des informations trouvées sur le réseau internet. Ces informations sont affichées sur des pages web et sont interconnectées entre elles en cliquant sur des liens hypertextes.
Il ne faut pas confondre le web et le réseau internet. Le réseau internet est un réseau physique de machines interconnectées entre elles, par le protocole IP alors que le web est l’ensemble des données trouvées sur le réseau internet. Toutes les informations stockées sur le web sont référencées sous l’acronyme www (world wide web).
Toutes les pages web sont accessibles depuis un programme : le navigateur web, comme Chrome, Mozilla Firefox, Safari,… L’information contenue dans ces pages est de nature diverse, comme par exemple des articles, des images,…
A partir de années 2000, le web se transforme, avec l’apparition de sites sociaux communautaires, appelés désormais réseaux sociaux (Facebook, Twitter, …). Le web continue de se développer de manière quasi exponentielle et il est désormais possible d’accéder à son contenu depuis n’importe quel terminal (téléphone, tablette, ordinateur,…).
L’élément le plus important pour naviguer sur une page web est le lien hypertexte. Il s’agit d’un élément (image, mot, paragraphe, …) sur lequel on peut cliquer à l’aide d’une souris et qui renvoie sur une autre page web. Généralement, ces liens sont surlignés et en les survolant à l’aide du curseur de la souris, celui-ci devient une main.
Pour afficher une page web dans un navigateur, il faut que cette page soit recherchée par l’utilisateur. Cette recherche est appelée une requête. L’utilisateur envoie en effet une demande au serveur, afin que ce dernier lui envoie les données. Une relation Client-Serveur s’établit entre l’utilisateur et le serveur, selon le protocole HTTP (hypertext transfert protocol), qui permet de demander l’affichage d’une page web.
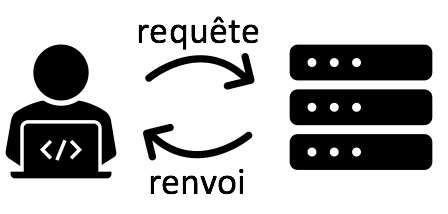
Exemple :
En cherchant une image sur un site web, on envoie une requête au serveur hébergeant l’image recherchée puis le serveur nous envoie les données de l’image sous forme de paquets pour l’afficher dans le navigateur.
Cependant, en envoyant une requête pour chercher un site web, il faut que l’adresse du site web soit référencée sur le World Wide Web, par une adresse unique symbolique ou adresse URL (Uniform Ressource Locator).
Exemple :
IL MANQUE LA CAPTURE D ECRAN DANS LA VIDEO.
On considère une requête HTTP.
On trouve en entête la demande au serveur pour l’envoi de ressources qui se fait à l’aide de la commande get.
La deuxième ligne contient le type de ressource attendu (il s’agit ici de l’html).
On retrouve enfin la date et la navigateur utilisé.
L’url de la ressource demandée indique l’arborescence du site où se trouve la ressource. En effet, un site internet est une structure en arborescence : page d’accueil, catégories, …
Une URL est composée de trois parties :
– une première partie détaillant le protocole de communication utilisé pour accéder à la page
– le nom de domaine de la page
– et le chemin vers la ressource.
On remarque aussi que chaque site internet possède une extension de domaine (noms de pays (.fr, .us,…), utilisation (.com, .edu, …), …).
Exemple :
On s’intéresse à l’url suivante :
https://www.lesbonsprofs.com/SNT
– http:// correspond au protocole de communication
– www.lesbonsprofs.com correspond au nom de domaine
– SNT indique le chemin de la ressource.
Enfin, l’extension de domaine est .com, qui indique que le site est associé à une activité commerciale.
Il existe des milliards de pages web sur le réseau internet et toutes ses pages web sont consultables grâce aux URL. Pour référencer ces pages WEB, le DNS (Domain Name System) permet de faire l’inventaire de ces pages et de les associer à des adresses IP.